Ce que Google dit, ce que Google montre
Commençons par lever une ambiguïté, parce qu’elle structure tout le reste.
L’annonce d’OKF parle de partage de la connaissance entre équipes et organisations. À la lecture, on imagine un format d’échange de données : je produis un bundle, vous le consommez, on se transmet du savoir.
Et pourtant. Quand on creuse un peu et qu’on ouvre les exemples livrés par Google dans son repo (les datasets GA4, Stack Overflow, Bitcoin) et l’agent d’enrichissement, on voit autre chose. Chaque concept décrit une table BigQuery : son schéma, le sens d’une colonne, les chemins de jointure, et un champ resource qui pointe vers la donnée, là où elle reste. La donnée ne voyage jamais.
Dit autrement : un concept qui décrit une table, c’est en pratique un skill. De la métadonnée, une grille de lecture pour un agent qui a déjà accès à l’entrepôt. Le bundle de référence est une couche d’annotation, un joli nom pour un skill posé sur des données que le producteur garde chez lui.
C’est utile, et c’est un usage parfaitement légitime du format. Mais c’est à un pas de la promesse. Le discours dit “partager la connaissance” ; la démonstration dit “décrire mes tables privées pour des agents”. Le pointeur suppose que le lecteur peut le suivre.
Au passage : non, OKF n’est pas un levier de search, ni un nouveau llms.txt à coller sur son site pour plaire aux IA. On a creusé ce point ailleurs (Article linkedin en anglais) et on ne le refait pas ici. Mais on le redit clairement, parce que le raccourci est tentant.
Reste alors une question que les exemples n’abordent pas : et si le lecteur ne peut pas accéder à votre entrepôt, et si la connaissance qui vaut d’être partagée, c’est le résultat déjà calculé ?
Là où on se situe
Marie Haynes, dans son billet sur OKF, pousse l’idée plus loin que la simple conversion de pages. Elle relève une piste : on pourrait vendre des bundles de connaissance experte. Un avocat, un comptable, un consultant qui empaquette ses processus propriétaires dans un bundle qu’une autre organisation intègre.
C’est exactement ce qu’on fait, en concret.
Trois idées circulent en ce moment autour des bundles OKF :
- Convertir ses pages en Markdown OKF, le réflexe GEO qui va à l’encontre même du concept OKF. Ce n’est pas ça.
- Construire le sien, à la Haynes, à partir de ses propres documents. Le principe, validé à petite échelle.
- Vendre un bundle de data + expertise. C’est là que notre PoC se situe.
Deux précisions sur ce qu’il y a dans nos bundles, parce qu’elles font la différence.
D’abord, un bundle contient un extrait de notre donnée Discover enrichie : vos articles, vos entités phares, vos pipelines de distribution comme ceux de vos concurrents, calculés à partir d’un jeu de données que vous ne pourriez pas produire vous-même.
Ensuite, on embarque à la fois l’expertise et la donnée. Les playbooks (comment lire et interroger le bundle) voyagent avec le jeu de données. Connaissance, expertise et données dans un seul artefact.
Et là, le contraste avec la démonstration de Google devient net. Google annote des tables qu’il garde. Notre bundle, lui, est la donnée plus la façon de la lire, dans un objet autonome : rien à synchroniser, rien à aller rechercher ailleurs, il reste chez le client. C’est le coeur de la proposition.
Comment un bundle est fabriqué
Un producteur déterministe (un script, aucun LLM dans la boucle, donc reproductible et auditable) lit notre réplica analytique et sérialise l’empreinte Discover d’un site sur une période, dans un bundle autonome. Quelques partis pris, qui sont aussi nos limites assumées :
- Capture, pas trafic. Nos chiffres viennent d’un échantillon de capture. Ce ne sont pas des volumes de trafic, d’audience ou de revenus. On compare des positions relatives (des parts, des scores), jamais des volumes absolus. On ne prétend pas avoir une donnée parfaite ; on a une donnée comparable.
- La performance se mesure en score et en jours. Le score (0 à 100) situe le meilleur jour d’un article face au plus fort article du système ce jour-là. Les jours en feed mesurent la persistance. Les deux indicateurs se conjuguent pour apporter de la nuance.
- Les entités d’abord, les topics à titre indicatif. Les thèmes auto-classés sont bruités (un portrait peut finir rangé en “humour”). On s’appuie sur les entités, et on confronte toujours aux titres avant de conclure.
Ces règles ne sont pas reléguées en note de bas de page : elles voyagent dans le bundle, dans un concept GUARDRAILS que l’agent lit en premier. La grille de lecture fait partie de la livraison.
Un bundle, ce sont des fichiers : les sections de données, les playbooks (les skills) et le contrat de lecture GUARDRAILS, dans un seul dossier.
Ce qu’on peut réellement en tirer
Un bundle n’est pas qu’une donnée : il embarque les recettes pour la lire. L’agent du client choisit le playbook qui correspond à sa question et produit l’analyse lui-même. Le menu, en résumé :
- pipeline-profile : quels mécanismes du feed vous portent, et quel profil d’éditeur vous êtes.
- content-footprint : sur quoi vous êtes visible, et ce qui décroche vos pics.
- pipeline-evolution : comment ce mix se déplace dans le temps.
Si vous donnez à votre agent non pas juste votre bundle, mais votre bundle et celui d’un (ou plusieurs concurrents), vous débloquez des playbook bonus :
- content-gap : où un concurrent est devant, et quoi publier pour combler.
- content-fit : ce que ses succès ont de naturellement transposable chez vous, avec des idées de titres dans votre propre style.
- pipeline-conquest : quels pipelines menés par un concurrent vous pouvez réalistement prendre.
Aucun de ces playbooks n’a besoin de revenir vers nous.
Voici deux exemples, sur données réelles, anonymisées.
La veine qu’un rédacteur n’aurait pas cherchée
Prenez un réseau de presse régionale et un concurrent régional plus large qui le surclasse, même fenêtre de 30 jours, même locale. En surface, ils se ressemblent : article médian identique, score 2 sur 100. Tout l’écart est dans la traîne. Le top-décile du concurrent est à 16 contre 7, et il produit des articles “forts” (score supérieur ou égal à 50) à un rythme environ 2,6 fois supérieur.
Chaque bundle classe les entités de deux façons : par fréquence de mention, et par score. Le classement par mention, pour les deux sites, n’est presque que de la géographie : il ne dit rien. Le classement par score, lui, révèle l’essentiel.
En haut de la table par score du concurrent, une grappe quasi invisible en volume : l’agriculture et l’économie rurale. Agroécologie : score médian 61, top-décile 90, persistance médiane 8 jours. Pas un pic d’un jour, une veine. Derrière, des portraits de fermes au premier degré (un jeune couple reprend une exploitation, un maraîcher se reconvertit en bio). Le genre porte tout le haut du classement du concurrent, autour de 90.
Et le réseau régional ? Il écrit le même genre. Mais à plat : quand il publie ce type de portrait, il score autour de 11 quand le concurrent score autour de 90. Même sujet, même locale, même mois. Il ne lui manquait pas le sujet. Il lui manquait le traitement qui le fait durer.
Aucun rédacteur ne tape “portrait d’éleveur de chèvres” dans un outil. Ce n’est pas une tendance, ça ne fait pas de pic, et en volume c’est du bruit. Ça n’apparaît que si on cesse de classer par fréquence pour classer par performance. C’est ça, le moteur.
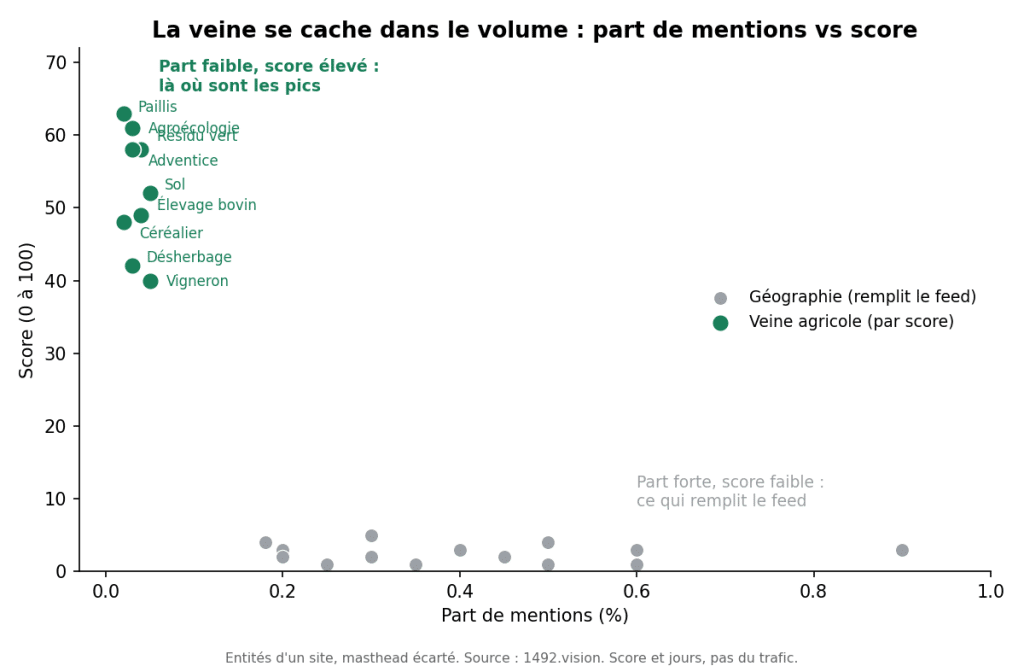
Les entités d’un site. Par part de mentions elles se ressemblent ; par score, la veine agricole se détache de la géographie qui remplit le feed.
Caractériser un site, finement
Sur un seul bundle, le même jeu de données dresse un portrait précis. Sur le réseau régional : une très large surface (une présence de masse), mais une intensité par article faible et concentrée. Score médian 2, top-décile 7, seulement 0,8 % d’articles forts, persistance médiane de 3 jours. Une traîne plate, et quelques pics. Le bundle nomme à la fois ce qui remplit le feed (la géographie, l’événementiel local, tous à faible score) et les veines à faible part mais fort score qui, elles, décrochent : épaves et découvertes patrimoniales (score médian 71), inventions du “génie ordinaire”, faune de saison. La caractérisation est actionnable sur un seul site, pas seulement en comparaison.
Deux questions, deux réponses : le gap et le fit
Une chose qu’on a dû expliciter en construisant les playbooks, et qui compte beaucoup pour Discover : “où suis-je en retard ?” (le gap) et “qu’est-ce qui me correspond naturellement ?” (le fit) sont deux questions différentes, avec des réponses différentes. Les confondre, c’est courir après du contenu qui ne prendra jamais.
Un exemple volontairement générique. Un site centré sur l’éducation et les enfants ; des concurrents qui performent sur le jardinage.
Le fit ne retient pas le jardinage : aucun ancrage commun avec une empreinte éducation-enfants. La recette dit, clairement, ne recommande pas ça. Une méthode qui ne dit que oui ne vaut pas qu’on lui fasse confiance ; c’est le non honnête qui donne du poids au oui.
Le gap, lui, signale le jardinage : une demande réelle, qui performe, et que le site n’a pas. Le signal qu’elle est atteignable ? Le thème marche chez plusieurs concurrents directs à la fois. Quand un sujet performe sur un ensemble de sites qui servent la même audience, c’est qu’aux yeux de Google les profils servis sont assez proches pour être compatibles.
Et le gap ne recommande pas “jardinage” brut. Il le recentre sur la force du site : jardiner avec les enfants (des semis qui poussent vite, un carré de balcon que les petits surveillent, des plantes non toxiques, un hôtel à insectes). Même demande prouvée, réancrée sur un terrain que le site tient.
Le fit répond à “qu’est-ce que je publie qui me ressemble”, le gap à “où est la demande prouvée près de moi”, et les coups les plus durables sont à l’intersection.
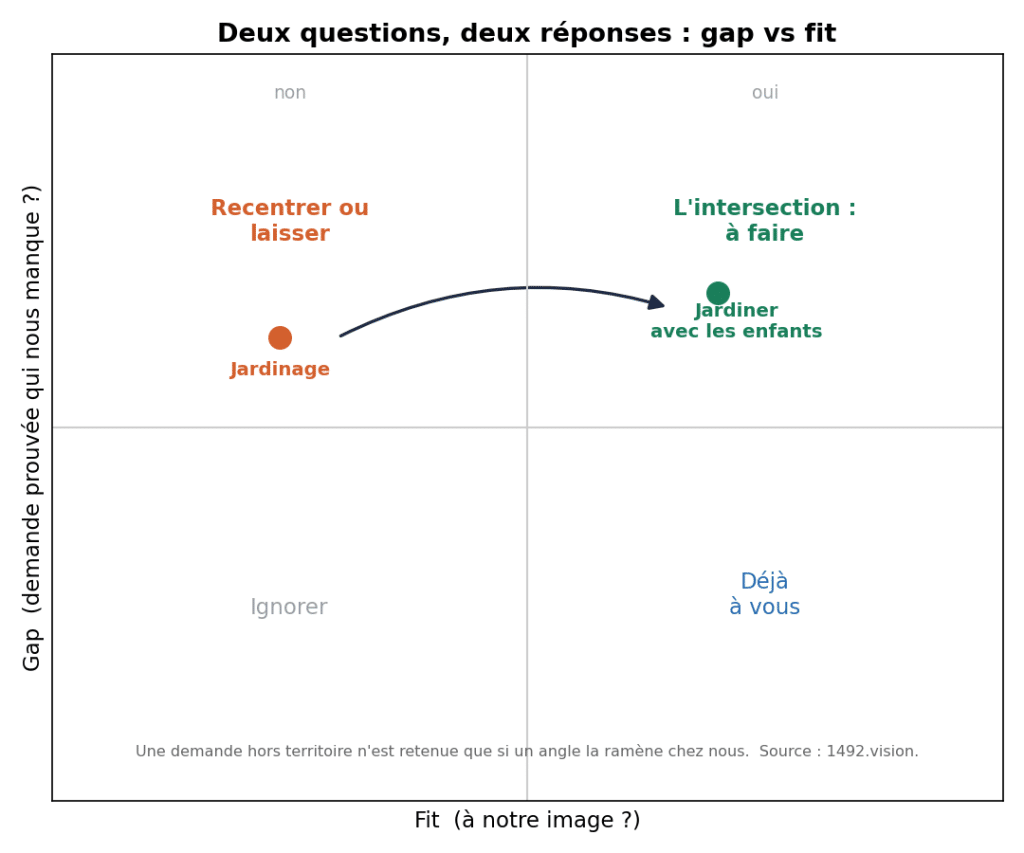
On déroule l’exemple avec plusieurs use cases sur notre site.
Deux façons de récupérer cette intelligence
Reste une question pratique : comment on vous livre tout ça. Deux modèles, et ils ne s’opposent pas.
Le premier, c’est le rapport clé en main, celui qu’on produit à la demande depuis un moment, et que les clients nous redemandent. Notre donnée, notre extraction, nos agrégats et nos tops, un raisonnement par-dessus, et un rapport personnalisé, assisté par IA, à partir d’un gabarit. Vous voulez la réponse, toute faite, avec notre lecture : c’est ce modèle. Le résultat est dense, le plus complet possible, technique.
Le second, c’est le bundle OKF que vous gardez. De la donnée enrichie, aggrégée, pré-filtrée, qui reste chez vous. Vous posez vos propres questions, vous itérez, vous comparez plusieurs bundles, vous y ajoutez votre propre donnée (la Search Console, par exemple), vous testez plus loin. Vous voulez posséder la donnée et continuer à l’interroger : c’est ce modèle.
Ce n’est pas l’un ou l’autre. Un rapport peut sortir d’un bundle, et un bundle survit à n’importe quel rapport. Le bundle, c’est votre carte ; vous la gardez.
Ce qu’on ne prétend pas
Pour finir, et parce que l’honnêteté fait partie du travail : Google n’a pas illustré cet usage, ses exemples décrivent des tables d’entrepôt. On a simplement expérimenté : poussé à bout le pari “l’agent sait lire” et mis notre donnée enrichie à l’intérieur du bundle. Ce que l’agent en tire, les deux exemples plus haut en sont la preuve, est allé plus loin que ce qu’on attendait d’un format aussi mince. C’est tout ce qu’on revendique, ni plus ni moins.
Le format est mince. Ce qu’on met dedans, et la façon de le lire, font tout. Le reste, les questions que vous posez, les comparaisons, les arbitrages éditoriaux, c’est vous qui les menez. Comme tout bon capitaine, c’est en naviguant dans vos propres données que vous ferez vos meilleures découvertes.
Sylvain Deauré, co-fondateur de 1492.vision.
Article de référence complet sur 1492
L’article “Open Knowledge Format : ce que Google montre, et ce qu’on en a fait” a été publié sur le site Abondance.


