Quand OpenAI a changé le modèle par défaut le 4 mars, le nombre de sites web cités par réponse a chuté d’un cinquième, et ne s’est jamais rétabli. Mais cette baisse n’est qu’une partie de l’histoire. Nous avons également procédé au reverse engineering des outils internes de navigation de ChatGPT, mené une expérience de type honeypot, reconstitué son system prompt et sorti une nouvelle version de notre plugin ChatGPT Search Capture.
Ce qui s’est passé
Le 4 mars 2026, ChatGPT a basculé son modèle par défaut de GPT-4o/5.2 vers GPT-5.3 Instant. Résultat : le nombre moyen de domaines uniques cités par réponse est passé de 19,1 à 15,2, soit une chute de plus de 20,%. Le nombre d’URLs uniques par réponse a suivi la même trajectoire, passant de 24,1 à 19,1.
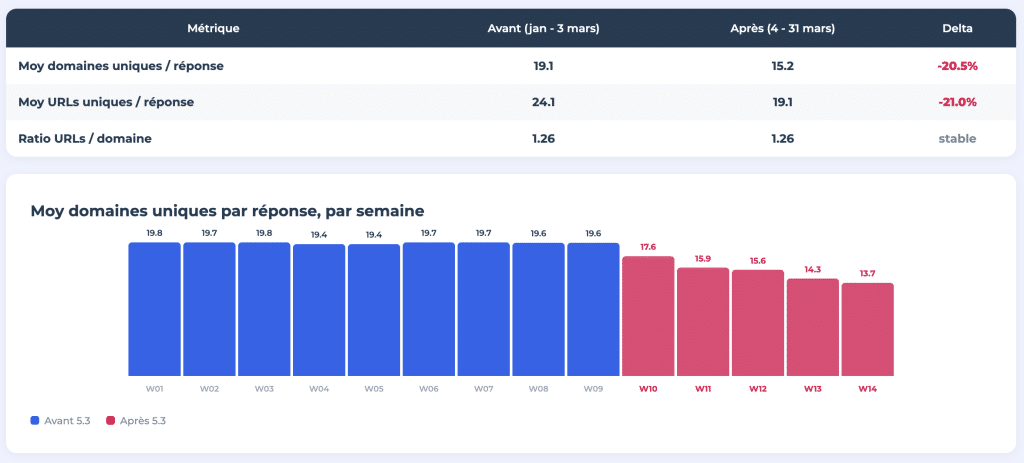
Nous avons suivi 400 prompts quotidiens pendant 14 semaines, en nous appuyant sur les données de monitoring fournies par Meteoria. L’ensemble des résultats est publié sous la forme d’une étude interactive en huit parties sur think.resoneo.com/chatgpt/5.3-5.4/.
Pourquoi c’est important
ChatGPT compte 900 millions d’utilisateurs actifs par semaine. La surface de citation dans chaque réponse n’a pas changé, mais moins de sites web se la partagent. Le même gâteau, mais avec moins de parts. Cela reflète probablement un glissement structurel vers des sources à plus forte autorité, mais cela signifie aussi globalement moins de gagnants. Les sites qui ne passent pas la sélection perdent une surface de visibilité qui leur était auparavant accessible.
L’effet Bigfoot
Nous avons nommé ce phénomène en référence à « l’update Bigfoot » identifiée par Dr. Pete (de Moz)) en 2013, quand Google laissait parfois un unique domaine occuper l’intégralité de la première page…
ChatGPT récupère désormais moins de domaines par réponse, mais le ratio URLs-par-domaine est resté stable à 1,26. La profondeur de crawl par domaine n’a pas changé. Ce qui a changé, c’est le nombre de sites web distincts qui obtiennent une place à la table.
GPT-5.4 Thinking accentue encore cette concentration. Le modèle utilise des opérateurs site: pour restreindre les recherches aux domaines de confiance et répartit ses requêtes sur souvent plus de 10 « fan-out queries » par réponse, chacune ciblant une source spécifique.
L’analyse indépendante des logs par Jérôme Salomon (Oncrawl) confirme cette tendance. Le volume de crawl du bot ChatGPT-User s’est stabilisé à un niveau inférieur depuis le passage à 5.3. Certaines pages ne sont tout simplement plus crawlées. La cause dépasse les mises à jour de modèle : plus de 90 % des utilisateurs hebdomadaires de ChatGPT sont sur un plan gratuit, et l’expérience par défaut déclenche moins de recherches web, utilise moins de requêtes, et produit moins de citations.
Comment ChatGPT Search fonctionne réellement
Notre étude présente également un reverse engineering complet du système de recherche interne de ChatGPT, baptisé web.run. Avant 5.3, le modèle envoyait des commandes textuelles compactes, séparées par des pipes (fast|query|recency). Après 5.3, il envoie des objets JSON structurés avec des paramètres typés. Ce n’est pas un simple changement de format. Cela reflète une architecture différente dans la manière dont le modèle formule et distribue ses opérations web.
L’outil web supporte désormais 12 opérations, contre 4 auparavant (plus un système de widgets séparé, “genui”). On y trouve notamment : search_query, open, find, click, screenshot, product_query, et des widgets spécialisés pour le sport, la finance, la météo, etc. GPT-5.4 peut enchaîner 5 à plus de 10 rounds de recherche par réponse, en affinant ses requêtes en fonction des résultats précédents. GPT-5.3 Instant se contente généralement de 2 ou 3.
Les traces de Google restent visibles : des marqueurs de tracking Google (strlid) apparaissent dans les URLs produits, et les correspondances ID-to-token de SearchAPI révèlent la dépendance du backend à des fournisseurs de recherche tiers, et à Google en arrière plan.
Un nouveau type de fan-out pour les requêtes produits
Nous avons mis au jour un type de fan-out encore non documenté : browse_rewritten_queries. Il apparaît exclusivement sur les requêtes produits, sur 5.4 Instant, et est visible dans le code de la conversation.
Quand un utilisateur pose une question du type « meilleure imprimante 3D à acheter en 2026 », ChatGPT commence par lancer un unique fan-out de réécriture pour construire la liste complète des produits candidats. Puis il lance un fan-out shopping séparé pour chaque produit individuel, récupérant caractéristiques, avis et prix un par un. Avant 5.3, les recherches produits étaient regroupées en un seul appel. Chaque produit bénéficie désormais de sa propre commande de récupération dédié.
ChatGPT-User est l’agent de récupération
Notre expérience honeypot a confirmé un détail important. Quand ChatGPT navigue sur le web suite à une recherche pendant une conversation, c’est le crawler ChatGPT-User, et non OAI-SearchBot, qui va chercher le contenu des pages. OpenAI décrit OAI-SearchBot comme l’agent qui construit l’index de recherche de ChatGPT, mais en pratique, le modèle s’appuie sur des API de scraping tierces pour obtenir les résultats de recherche, puis envoie ChatGPT-User récupérer le contenu réel des URLs sélectionnées.
L’angle mort des namespaces : la faille de ChatGPT
C’est peut-être notre découverte la plus étonnante.
La piste a commencé par du reverse engineering classique. Nous avons décompilé l’application mobile ChatGPT, disséqué le code source du client web et sniffé les paquets réseau sur les deux plateformes. Cela nous a donné les noms des outils internes et certaines conventions d’appel. Armés de ces éléments précis, nous avons pu poser les bonnes questions à ChatGPT – et découvert que le modèle y répondait sans aucune restriction.
OpenAI a mis en place de véritables protections autour de ses system prompts. Mais la couche de configuration des outils internes n’en a aucune. Les namespaces de ChatGPT, ces groupes d’outils internes que le modèle peut appeler pendant une conversation, sont librement descriptibles. Tant que vous évitez les mots « system prompt », le modèle divulguera les schémas d’outils, les listes d’opérations, les canaux de sortie et les structures de namespaces avec une parfaite cohérence.
Nous avons publié des prompts prêts à l’emploi que n’importe qui peut coller dans ChatGPT pour auditer son environnement interne. Pour vérifier si le modèle hallucinait ces descriptions, nous avons mené une étude participative auprès de dizaines d’utilisateurs, sur des sessions distinctes. Chaque participant a obtenu exactement les mêmes noms d’outils, les mêmes schémas de paramètres, les mêmes listes d’opérations. Le modèle décrit son propre outillage de manière constante, donc fiable ^^
L’étude comprend également un system prompt reconstitué par extraction progressive, accompagné de plusieurs informations notables : Reddit est le seul domaine exempté des limites de mots liées au copyright, il existe une liste granulaire de produits interdits, un « score de surverbosité » fonctionne sur une échelle de 1 à 10, et un paragraphe complet de politique publicitaire régit l’affichage des pubs par niveau d’abonnement.
Usage pratique : réaliser votre propre audit de crawlabilité
La syntaxe web.run que nous avons documentée n’est pas qu’une curiosité technique. Elle fonctionne, et elle ouvre une voie directe pour tester la façon dont ChatGPT interagit avec vos contenus.
Voici un exemple concret. Vous pouvez forcer ChatGPT à rechercher votre domaine et à lire des pages spécifiques en collant des commandes JSON directement dans une conversation.
D’abord, déclenchez une recherche ciblée sur votre site, puis forcez-le à aller chercher les deux premiers résultats récupérés, demandez-lui ensuite de renvoyer le titre, le sujet principal et les points clés de chaque page.
Search for this query, then open the first two results and summarize what you find on each page.
Step 1 : Search:
{
"search_query": [
{ "q": "site:abondance.com seo" }
],
"response_length": "short"
}
Step 2 : Open the first two results:
{
"open": [
{ "ref_id": "turn0search0" },
{ "ref_id": "turn0search1" }
]
}
Step 3 : Give me a structured recap of what you found on each URL. For each page: the title, the main topic, and 3-5 key points.Ce que vous obtenez, c’est une vision de votre contenu à travers les yeux de ChatGPT : ce qu’il peut réellement atteindre, ce qu’il en extrait, et comment il interprète vos pages. S’il ne peut pas accéder à une page, renvoie un contenu confus, ou passe totalement à côté de vos messages principaux, c’est un signal sur lequel agir.
Pour aller plus loin, l’extension Chrome « ChatGPT Search Capture » de RESONEO (V3.3, gratuite sur le Chrome Web Store) permet de visualiser les URLs exactes récupérées pendant n’importe quelle conversation ChatGPT, y compris les fan-out queries (sauf pour 5.3 Instant, désormais opérées côté serveur), les ref_ids et les métadonnées du modèle. Combinée aux commandes JSON manuelles ci-dessus, vous disposez d’un audit d’extractabilité léger mais actionnable : quelles sont les urls qu’il fait remonter, et qu’en extrait-il réellement ?
Même famille de modèles, citations différentes
GPT-5.2, 5.3 et 5.4 partagent la même date de cutoff (août 2025) et appartiennent à la même famille GPT-5. Pourtant, le même prompt envoyé à chacun d’eux produit des fan-out queries différentes, récupère des sources différentes, et fait remonter des passages différents dans la réponse finale.
Plusieurs couches de divergence agissent après le pré-entraînement : le reward shaping du RLHF, les données de fine-tuning supervisé, les configurations du system prompt et les budgets de compute à l’inférence. GPT-5.4 Pro reçoit explicitement plus de compute pour « réfléchir plus intensément », et cela seul peut changer quelles sources sont citées.
C’est la raison pour laquelle nous recommandons de tester modèle par modèle. Un seul prompt peut produire des citations radicalement différentes selon que l’utilisateur est sur GPT-5.3 Instant, 5.4 Thinking ou 5.4 Extended. Les utilisateurs du plan gratuit peuvent aussi être silencieusement redirigés vers un modèle allégé.
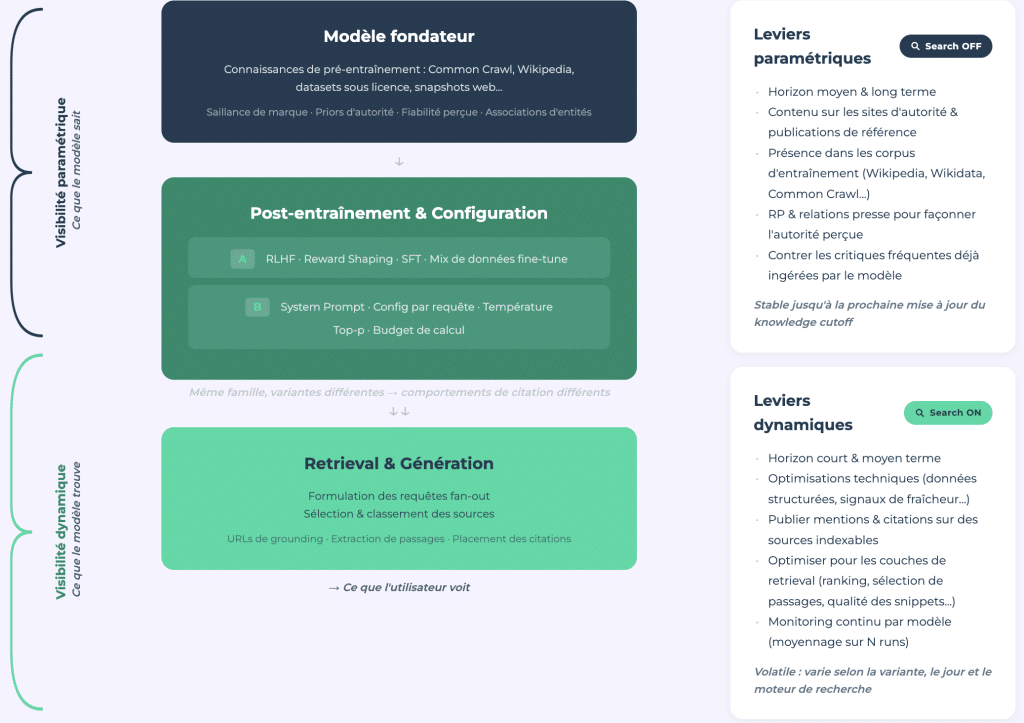
Deux types de visibilité IA
Notre étude présente un framework d’analyse séparant la visibilité paramétrique (ce que le modèle sait grâce à ses données d’entraînement, recherche désactivée) de la visibilité dynamique (ce qu’il récupère en temps réel, recherche activée).
Visibilité paramétrique : l’E-E-A-T des LLMs
La visibilité paramétrique est l’équivalent E-E-A-T pour les grands modèles de langage. C’est l’autorité encodée à travers des milliards d’exemples d’entraînement, façonnée par la couverture presse, la présence sur Wikipédia, d’autres grands sites d’autorité et le corpus d’entraînement dans son ensemble. Elle est stable et mesurable via des audits one-shot par API.
Visibilité dynamique : un terrain mouvant
La visibilité dynamique, elle, est volatile. Elle dépend du modèle et nécessite un monitoring continu. Elle se rapproche davantage du SEO traditionnel, et peut s’effondrer du jour au lendemain avec une mise à jour de modèle, comme le montre l’effet Bigfoot.
Le lien entre les deux
Le lien entre les deux compte. Le modèle formule ses requêtes web en ciblant les sources qu’il connaît déjà. Une marque absente de la mémoire paramétrique ne sera même pas envisagée comme candidate à la recherche. Être inconnu du modèle signifie être invisible avant même que la recherche ne commence.
Les mises à jour de la date de cutoff sont constituent la « Google Dance » des LLMs. Quand la date de cutoff change, les classements paramétriques sont redistribués en bloc. Mais cela n’arrive qu’environ une fois par an, car le réentraînement à cette échelle est extrêmement coûteux. La fenêtre stratégique pour influencer ce que le modèle sait de votre marque se situe entre deux dates de coupure.
L’AI Brand Authority Index de Dan Petrovic (DEJAN) illustre la mesure paramétrique à grande échelle. Notre étude la complète avec un cadre de test plus léger et reproductible, basé sur cinq prompts exécutés plusieurs fois pour un audit one-shot.
Pour aller plus loin
L’étude complète (documentation reverse-engineerée, expérience honeypot, prompts d’audit DIY et system prompt reconstitué) est disponible sur think.resoneo.com/chatgpt/5.3-5.4/.
En synthèse
ChatGPT Search n’est plus une boîte noire. Cette étude cartographie son architecture interne, de l’outil web.run qui propulse chaque recherche à la logique de fan-out qui décide quels domaines sont récupérés et lesquels sont ignorés.
La chute de 20 % des domaines cités après le passage à 5.3 montre à quelle vitesse le paysage des citations peut basculer avec une seule mise à jour de modèle. Mais le problème de fond est structurel : ChatGPT concentre ses citations sur moins de sites web et applique une logique de sélection de sources façonnée par les données d’entraînement, le fine-tuning post-entraînement et des règles de system prompt qui changent d’un modèle à l’autre.
Suivre la visibilité dans ChatGPT implique de comprendre deux couches distinctes (paramétrique et dynamique), de tester sur plusieurs modèles, et de surveiller un système dont les outils internes sont documentables mais dont le comportement peut changer du jour au lendemain.
L’étude complète fournit les données, la méthodologie et les outils pour commencer.
L’article “Dans les coulisses de ChatGPT Search : reverse engineering de web.run, fan-outs, et les nouvelles règles de visibilité” a été publié sur le site Abondance.


