L’Arcep, le régulateur français des télécoms, a publié en janvier 2026 un rapport de 104 pages consacré à l’impact de l’IA générative sur l’internet ouvert. Nourri d’une étude empirique menée sur trois services d’IA (Mistral, Gemini, Perplexity), ce document apporte des données concrètes sur des questions qui préoccupent directement les professionnels du SEO et les éditeurs de sites : baisse du trafic, opacité des sources citées par les IA, montée des crawlers, et émergence du GEO.
Ce qu’il faut retenir :
- Le trafic en provenance des moteurs de recherche va continuer à baisser avec la généralisation des résumés IA.
- Être bien positionné sur Google ne suffit plus à exister dans les réponses des IA.
- Les règles du GEO sont encore floues et propres à chaque service d’IA — ce qui complique toute stratégie.
- La maîtrise des crawlers et du robots.txt devient un enjeu technique urgent pour les éditeurs.
- L’IA agentique va créer une nouvelle couche d’intermédiation, potentiellement encore plus opaque que les précédentes.
Du SEO au GEO : un basculement en cours
Le constat central du rapport est sans ambiguïté : les IA génératives sont en train de devenir de nouvelles “portes d’entrée” vers l’internet, au même titre que les moteurs de recherche ou les réseaux sociaux. L’utilisateur ne navigue plus de lien en lien ; il pose une question et reçoit une réponse synthétique, formulée en langage naturel. Ce glissement d’un “moteur de recherche” vers un “moteur de réponse” redéfinit en profondeur les règles du jeu pour les éditeurs.
Pour les professionnels du référencement, cela se traduit par une évolution majeure des pratiques : les stratégies SEO classiques, fondées sur la structure du site, les signaux d’autorité de domaine, la fraîcheur du contenu, ne suffisent plus. L’enjeu désormais n’est plus d’apparaître en bonne position dans une liste de résultats, mais d’être identifié comme source pertinente par un agent génératif et effectivement cité dans sa réponse. Cette nouvelle discipline est communément désignée sous le terme de GEO (Generative Engine Optimization).
L’étude IMPACTIA du PEReN, menée sur 200 000 citations analysées, apporte un éclairage précieux : les sources citées par les IA génératives se recoupent seulement partiellement avec les premiers résultats Google. Le taux d’intersection avec le top 5 de Google ne dépasse pas 19 à 32 % selon les outils testés. Autrement dit, être bien positionné sur Google ne garantit plus d’être cité par une IA, et inversement.
Trafic en chute libre : des chiffres qui alarment
Le rapport de l’Arcep de janvier 2026 confirme ce que de nombreux éditeurs ressentent déjà sur leurs analytics : la généralisation des résumés IA fait baisser le trafic entrant. L’exemple le plus frappant vient d’une étude du Pew Research Center, citée par l’Arcep : les utilisateurs exposés à un résumé via Google AI Overviews ne cliquent sur une source externe que dans 8 % des cas.
Même Wikipédia, pourtant le domaine le plus cité par toutes les IA étudiées (jusqu’à 19 % des citations dans la catégorie “histoire”), fait état d’une baisse de trafic notable depuis l’arrivée des outils d’IA générative. Si même les sites les plus référencés par ces outils voient leur fréquentation reculer, la situation des éditeurs de taille plus modeste est logiquement plus préoccupante encore.
Cette tendance soulève également une question économique : la visibilité conditionnant en grande partie les revenus publicitaires et les abonnements, une baisse durable du trafic menace directement la viabilité financière des éditeurs indépendants. Des sites d’information rapportent de fortes baisses d’audience depuis que les grandes plateformes ont intégré des fonctionnalités d’IA générative dans leurs interfaces de recherche.
Concentration des sources : 2 % des domaines captent 49 % des citations
L’un des résultats les plus marquants de l’étude IMPACTIA concerne la concentration extrême des sources mobilisées par les IA. Sur 9 206 noms de domaine cités, les 2 % les plus référencés, soit 185 domaines, représentent à eux seuls près de 49 % des 200 000 citations analysées. À l’autre extrémité, 72 % des domaines ne sont cités qu’entre 1 et 10 fois au total.
Wikipédia s’impose comme la source dominante dans toutes les catégories testées. On trouve ensuite, de façon surprenante, des sites d’aide aux devoirs comme studysmarter.fr ou alloprof.ca. Les critères qui expliquent ces choix restent largement opaques : les algorithmes de sélection et de pondération des sources par les IA ne sont ni documentés, ni standardisés, ni accessibles aux éditeurs.
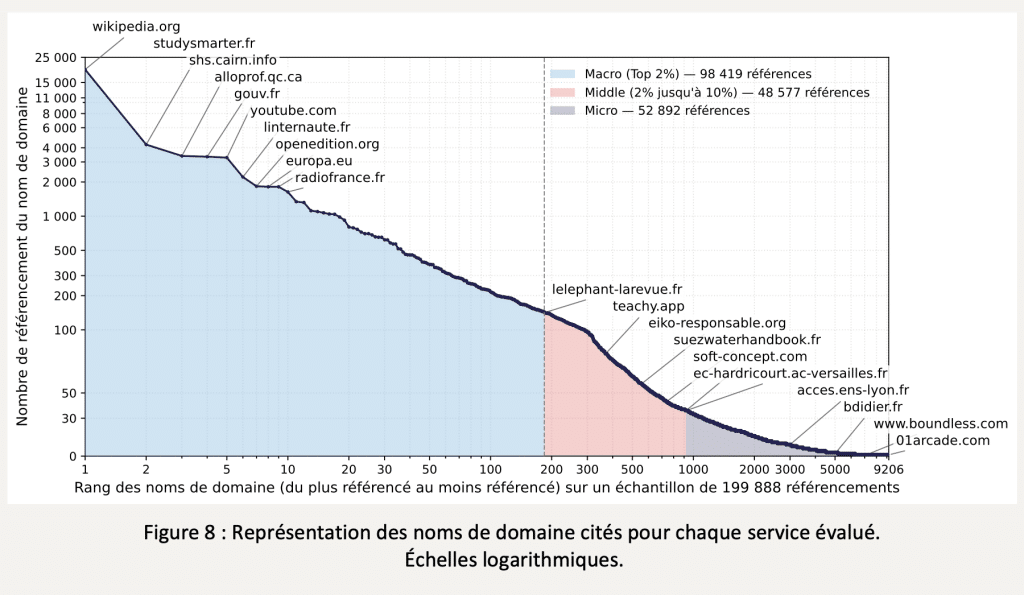
Autre enseignement de taille : chaque service d’IA a ses propres biais de citation. Certains domaines très cités par l’un sont quasi absents chez ses concurrents. Cette variabilité rend d’autant plus difficile la construction d’une stratégie de visibilité cohérente pour les éditeurs, qui ne peuvent pas s’appuyer sur des règles stables et universelles comme c’est le cas avec le SEO classique.
Crawlers et robots.txt : une relation devenue conflictuelle
Sur le plan technique, le rapport pointe une tension croissante autour des robots d’indexation (crawlers) utilisés par les acteurs de l’IA pour collecter des données sur le web. Depuis 2022, plusieurs éditeurs de sites enregistrent une augmentation significative de leur trafic lié aux bots. Cloudflare estime que le trafic des crawlers pourrait dépasser le trafic humain dès 2029.
Le protocole robots.txt, conçu à l’origine pour permettre aux éditeurs de contrôler l’indexation de leurs pages, se retrouve fragilisé. Certains crawlers d’IA ne respectent pas ses directives, voire saturent les serveurs au point de provoquer des indisponibilités. La fondation Wikimédia indique que 65 % de son trafic provient désormais de robots.
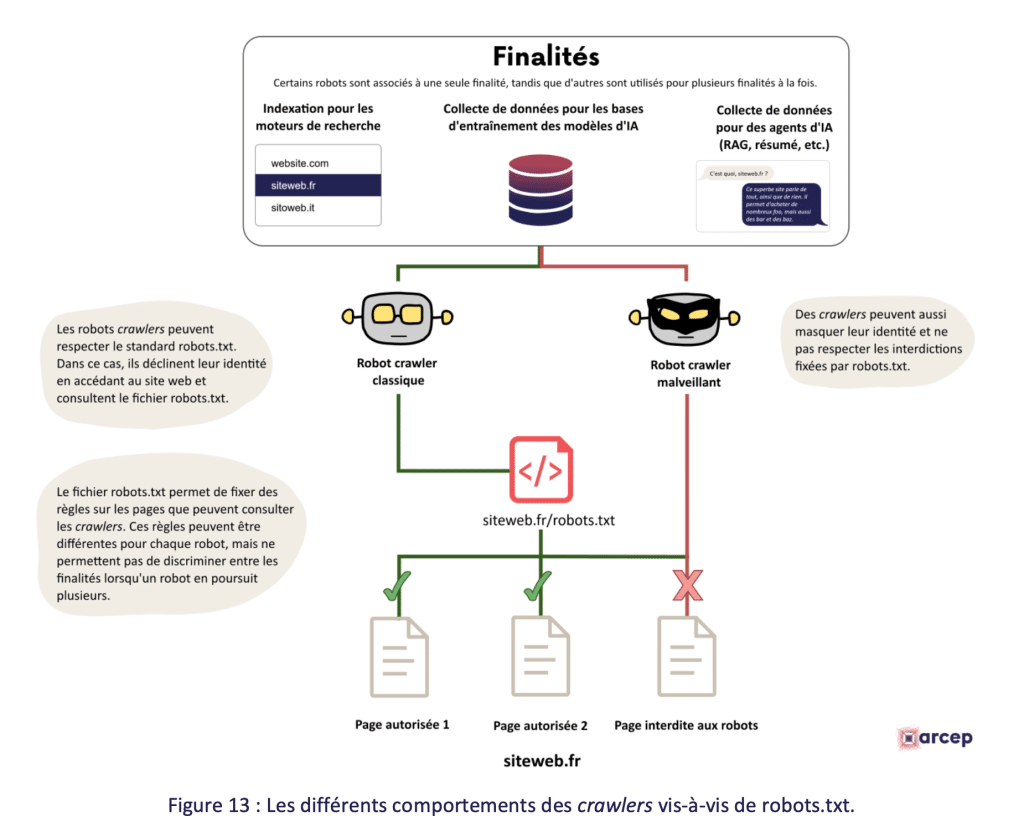
Le problème central est l’absence de mécanisme permettant de distinguer techniquement les crawlers d’IA des crawlers de moteurs de recherche : bloquer les uns, c’est risquer de bloquer les autres, et donc pénaliser son propre référencement naturel. Face à ce vide, de premières solutions émergent :
- Le modèle pay-per-crawl de Cloudflare (utilisant le code HTTP 402 “Payment Required”), qui permet aux éditeurs de monétiser l’accès de leurs contenus aux robots d’IA.
- Le projet ai.txt (Artificial Intelligence Access Protocol), une évolution du robots.txt permettant de préciser, de façon granulaire, les conditions d’utilisation des données selon leur usage : entraînement, indexation, ou fonctionnalités agentiques.
- Des travaux de normalisation au W3C et à l’IETF pour adapter les protocoles existants aux spécificités de l’IA générative.
L’IA agentique : le prochain défi pour la visibilité des services
Le rapport insiste également sur l’émergence de l’IA agentique, des systèmes capables non seulement de générer du texte, mais aussi d’agir directement au nom de l’utilisateur : réserver un billet, effectuer un achat, accéder à un service tiers. Dans ce schéma, c’est l’agent qui choisit les prestataires, les applications et les services à mobiliser, et non plus l’utilisateur.
Des accords commerciaux ont déjà été conclus : OpenAI avec Walmart, Etsy et Shopify ; Claude (Anthropic) avec Notion, Canva et Stripe ; Copilot avec OpenTable, Kayak et Instacart. Les services non partenaires risquent simplement de ne pas être proposés aux utilisateurs, sans que ces derniers en aient conscience. Cette logique de “référencement fermé” constitue un risque structurel pour tout acteur numérique qui ne dispose pas des moyens de négocier de tels accords.
L’article “Votre site existe-t-il encore pour l’IA ? L’éclairage du dernier rapport Arcep” a été publié sur le site Abondance.


